We are working on audio-visual speech recognition, the process of automatically recognizing speech by lipreading. Supplementing traditional acoustic features with visual speech information can lead to robust automatic speech recognizers that can be deployed in very challenging acoustic environments, such as airplane cockpits, car cabins, or loud clubs, which are far beyond the reach of current audio-only speech recognition systems. We have worked on many aspects of the problem, ranging from adaptive fusion of asynchronous multimodal features, to compact visual speech facial representations, to efficient implementations for building real-time prototypes, and beyond.
Multimodal Fusion by Adaptive Compensation of Feature Uncertainty
Our goal is to develop multimodal fusion rules which automatically adapt to changing environmental conditions. In the context of audio-visual speech recognition, such multimodal fusion rules should automatically discount the share of degraded features in the decision process. For example, in the presence of acoustic noise bursts the audio information should be discarded and similarly for the visual information in the case of face occlusions.
align=”center”>
Figure 2. Multimodal uncertainty compensation leads to adaptive fusion. As the y_2 stream is contaminated by more noise, classification decision is influenced mostly by the cleaner y_1 stream.
We have come up with a conceptually elegant framework based on uncertainty compensation which can address this problem. This amounts to explicitly modeling feature measurement uncertainty and studying how multimodal classification and learning rules should be adjusted to compensate for its effects. We show that this approach to multimodal fusion through uncertainty compensation leads to highly adaptive multimodal fusion rules which are easy and efficient to implement. What’s more, our technique is widely applicable and can be transparently integrated with either synchronous or asynchronous multimodal sequence integration architectures, such as Product-HMMs. The adaptive fusion effect of uncertainty estimation is illustrated in Figure 2. For further information on the method we refer to Papandreou et al. (2009). We have extended the popular Hidden Markov Model Toolkit (HTK) so as to support training and decoding under uncertainty compensation for multi-stream HMMs; see the software section of the page.
Active appearance model features for visual speech description
While extraction of acoustic speech features is well studied, extraction of visual speech descriptors is relatively less explored. Our goal has been to capture visual speech information in low-dimensional visual speech descriptors, which should be compact, relatively invariant to the identity of the speaker and the scene illumination, and fast to compute so as to allow for real-time processing.
Figure 3. Left: Linear sub-spaces capturing the shape and appearance variability in AAMs. Right: Video demonstrating automatic visual feature extraction with active appearance models and its use for audio-visual automatic digits recognition under noisy acoustic conditions. The ellipses around each face landmark indicate the AAM’s localization uncertainty.
For visual feature extraction we build on the active appearance model (AAM) framework. Active appearance models analyze the shape and appearance variability of human faces in low-dimensional linear spaces learnt from training data – see Figure 3. In our visual front-end the AAM mask is initialized using a face detector, thus leading to fully automatic visual feature extraction. By adapting the AAM’s mean shape and apperance vectors, we can achieve improved invariance to inter-speaker variability. The resulting visemic AAM thus concentrates its modeling capacity to speech-induced variability. To allow for real-time performance, we have developed improved fast and accurate algorithms for AAM fitting. For more information, we refer to Papandreou et al. (2009) and Papandreou and Maragos (2008). Our AAM software is further described in the AAMtoolspage.
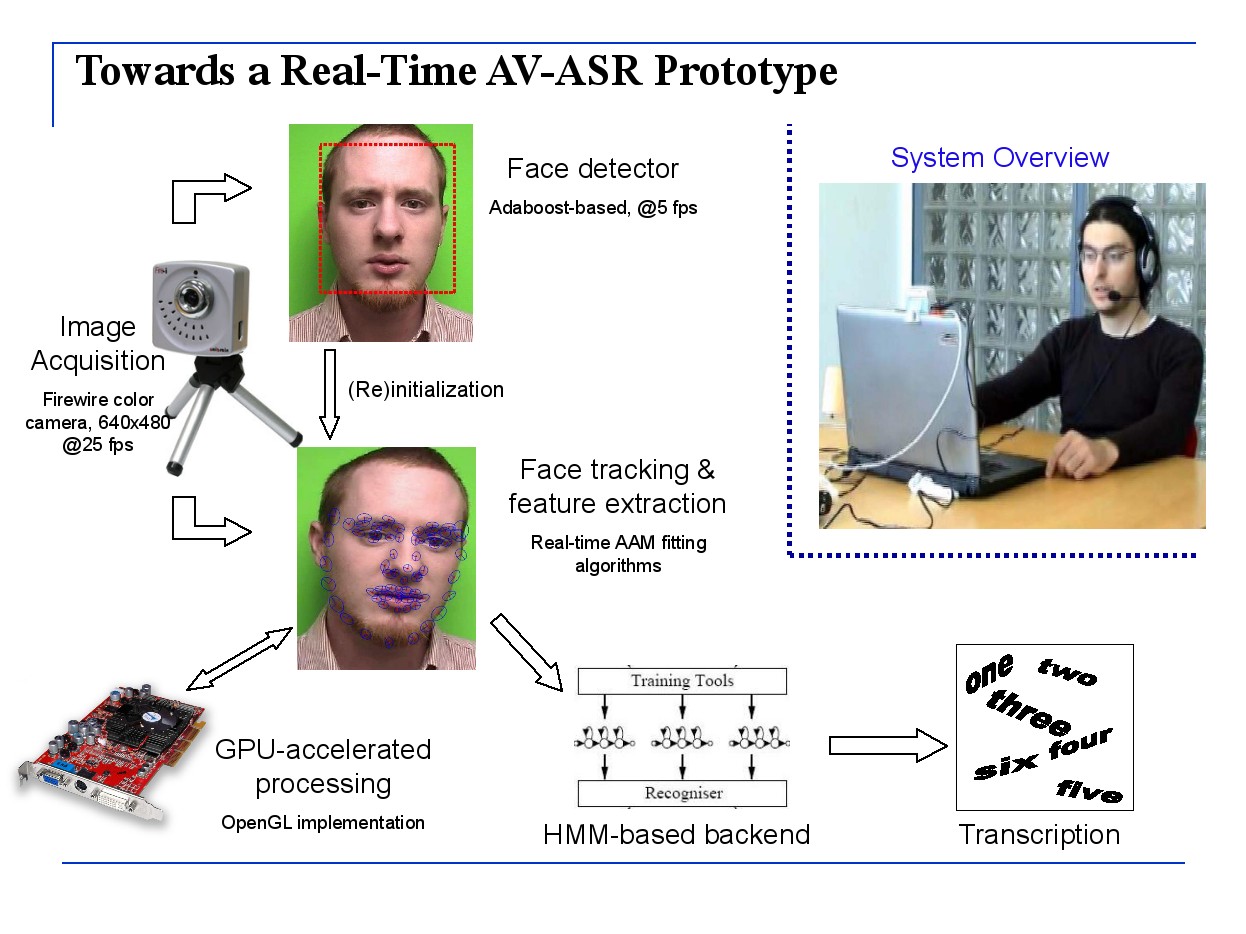
Towards practically deployable audio-visual automatic speech recognition (AV-ASR), we have built a proof-of-concept laptop-based AV-ASR prototype which: (i) uses consumer microphone and camera to capture the speaker; (ii) performs visual/audio feature extraction, as well as speech recognition on the laptop in real-time; (iii) is robust to failures of a single modality, such as visual occlusion of the speaker’s face; and (iv) automatically adapts to changing acoustic noise levels. The prototype’s interface has been designed and developed by our TSI-TUC collaborators (M. Perakakis and A. Potamianos).