Multimodal Visual Concept Learning with Weakly Supervised Techniques

Overview
Despite the availability of a huge amount of video data accompanied by descriptive texts, it is not always easy to exploit the information contained in natural language in order to automatically recognize video concepts. Towards this goal, in this paper we use textual cues as means of supervision, introducing two weakly supervised techniques that extend the Multiple Instance Learning (MIL) framework: the Fuzzy Sets Multiple Instance Learning (FSMIL) and the Probabilistic Labels Multiple Instance Learning (PLMIL).
The former encodes the spatio-temporal imprecision of the linguistic descriptions with Fuzzy Sets, while the latter models different interpretations of each description’s semantics with Probabilistic Labels, both formulated through a convex optimization algorithm. In addition, we provide a novel technique to extract weak labels in the presence of complex semantics, that consists of semantic similarity computations.
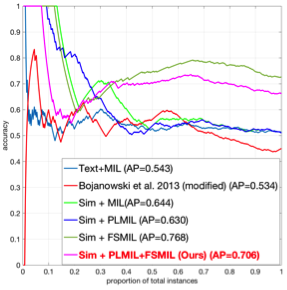
We evaluate our methods on two distinct problems, namely face and action recognition, in the challenging and realistic setting of movies accompanied by their screenplays, contained in the COGNIMUSE database. We show that, on both tasks, our method considerably outperforms a state-of-the-art weakly supervised approach, as well as other baselines.
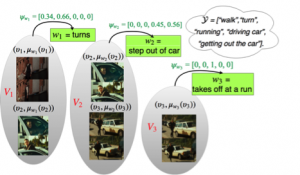
Illustration of Multiple Instance Bags in the context of the FSMIL and PLMIL methods.
Results
Face Recognition Task

Action Recognition Task
Publications
- Giorgos Bouritsas, Petros Koutras, Athanasia Zlatintsi and Petros Maragos,
Multimodal Visual Concept Learning with Weakly Supervised Techniques ,
,
Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, Utah, USA, June 2018[Bibtex] [arXiv] [Code] [Poster]

Software
- The code for the end-to-end implementation of the multimodal system, as well as the weakly supervised learning techniques is available on GitHub.
- We also release the Dynamic Time Warping algorithm for the script-subtitle alignment as provided by Dr. Laptev and Dr. Bojanowski, along with some example data.
Data
- The raw data are publicly available as part of the COGNIMUSE database.
- We also provide the precomputed visual features, their ground truth labels and the weak labels that we extracted from the accompanying documents. [movie data] [.zip]
- You can find the action categories that were used as label set here