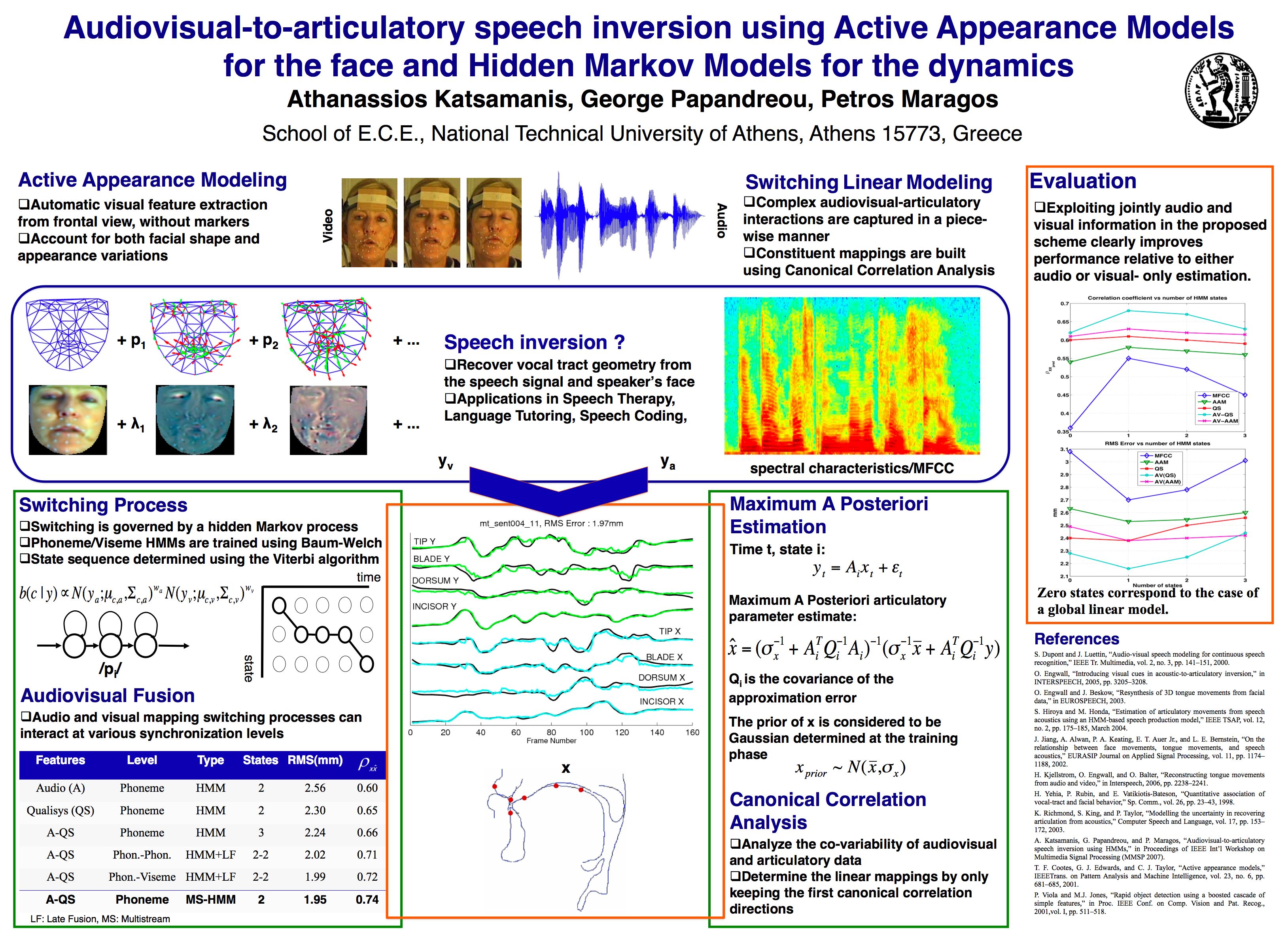
Audiovisual Speech Inversion

Figure 1. Recovering the underlying vocal tract from audiovisual speech
Overview
We are working on an inversion framework to identify speech production properties from audiovisual information. Our system is built on a multimodal articulatory dataset comprising ultrasound, X-ray, magnetic resonance images, electromagnetic articulography data as well as audio and (stereo)visual recordings of the speaker. Visual information is captured via stereovision or active appearance modeling of the face while the vocal tract state is represented by a properly trained articulatory model. The audiovisual-to-articulation relationship is approximated by an adaptive piecewise linear mapping. The presented system can recover the hidden vocal tract shapes and may serve as a basis for a more widely applicable inversion setup.
Speech Modeling
Speech is considered to be a multimodal process. Audio and visual observations are dependent upon hidden vocal tract states which in turn follow the underlying sequence of speech production states. Articulatory variations may not be reflected simultaneously on the observed streams and so, the implied speech model may be schematized as in Figure 2.

Figure 2. Audiovisual speech model with asynchronicity between the observed streams.
In practice, this can be implemented by means of hidden Markov models as given in Figure 3. Visemes and phonemes are modeled separately allowing for greater flexibility. Each hidden state corresponds to a different mapping between the vocal tract and the observations. After determining the optimal state sequence for the two modalities a sequence of hidden vocal tract states can be recovered by maximum a posteriori estimation and proper fusion.

Figure 3. Separate viseme and phoneme modeling using HMMs. Late fusion is applied to get the final estimate for the underlying vocal tract state sequence.
Vocal Tract Representation
Regarding the representation of the vocal tract, several options have been proposed, each satisfying certain requirements. In our work, we have used two alternatives. The representation via the coordinates of points on significant articulators as tracked by Electromagnetic Articulography is more realistic but spatially sparse and not so informative for the entire vocal tract state (Figure 4).

Figure 4. Placement of the Electromagetic Articulography sensors in the MOCHA database.
A much more informative representation is the one achieved via an articulatory model that can describe the geometry or the cross-sectional area of the vocal tract and is controlled by a limited number of parameters. We have built such a model using vocal tract contours annotated on X-ray data of the speaker. It describes the midsagittal vocal tract shape. A semi-polar grid is properly positioned on the midsagittal plane, Fig.5(a), and the coordinates of the intersection points with the vocal tract boundary are found, Fig.5(b). Principal Component Analysis (PCA) of the derived vectors determines the components of a linear model that can describe almost 96% of the shape variance using only 6 parameters.

Figure 5. Articulatory model built on X-ray data.
Audiovisual Speech Representation
Speech acoustics are captured via Mel Frequency Cepstral Coefficients. For the face, we apply active appearance models (Figure 6). These are generative models of object appearance and have proven particularly effective in modeling human faces for diverse applications, such as face recognition or tracking. As visual features we use the analysis parameters after projecting speaker’s face on a basis of eigenfaces. For details, please refer to Katsamanis et al. (2009). For the corresponding AAM fitting algorithm please refer to Papandreou and Maragos (2008) and check the AAMtools software page. Visual AAM features for the female speaker of the MOCHA database are also available and can be downloaded from here (9.7 MB zip file – please check the README file first).
Figure 6. Mean appearance and first two components of the active appearance model.
People




Publications
- A. Katsamanis, G. Papandreou and P. Maragos,
Face Active Appearance Modeling and Speech Acoustic Information to Recover Articulation,
IEEE Transactions on Audio, Speech and Language Processing, vol. 17, no. 3, pp. 411-422, Mar. 2009.[pdf] [bib] - A. Katsamanis, T. Roussos, P. Maragos, M. Aron and M.-O. Berger,
Inversion from Audiovisual Speech to Articulatory Information by Exploiting Multimodal Data,
International Seminar on Speech Production (ISSP 2008), Strasbourg, France, Dec. 2008.[pdf] [bib] [presentation] - A. Katsamanis, G. Ananthakrishnan, G. Papandreou, P. Maragos, O. Engwall,
Audiovisual Speech Inversion by Switching Dynamical Modeling Governed by a Hidden Markov Process,
European Signal Processing Conference (EUSIPCO 2008), Lausanne, Switzerland, Aug. 2008.[pdf] [bib] - G. Papandreou and P. Maragos,
Adaptive and Constrained Algorithms for Inverse Compositional Active Appearance Model Fitting,
Proc. IEEE Int’l Conf. on Computer Vision and Pattern Recognition (CVPR-2008), Anchorage, AL, June 2008.[pdf] [appendix] [bib] [software] - A. Katsamanis, G. Papandreou, and P. Maragos,
Audiovisual-to-Articulatory Speech Inversion Using Active Appearance Models for the Face and Hidden Markov Models for the Dynamics,
Proc. IEEE Int’l Conference on Acoustics, Speech, and Signal Processing (ICASSP-2008), Las Vegas, NV, U.S.A., Mar.-Apr. 2008.[pdf] [poster] [bib] - A. Katsamanis, G. Papandreou, and P. Maragos,
Audiovisual-to-Articulatory Inversion Using Hidden Markov Models,
Proc. IEEE Workshop on Multimedia Signal Processing (MMSP-2007), pp. 457-460, Chania, Greece, October 1-3, 2007.[pdf] [bib]
{kind=link}
Data
- AAM-based visual features for the female speaker fsew0 of the MOCHA database.[zip archive] [README]
Acknowledgements
We would like to thank M. Aron, M.-O. Berger, Y. Laprie and E. Kerrien at LORIA for making the articulatory data available and all the ASPI participants for very fruitful discussions. Further, we would like to thank K. Richmond from CSTR in Edinburgh for providing us the videos of the MOCHA database.
Our work is supported by European Community FP6 FET ASPI (contract no. 021324) and partially by grant ΠENEΔ-2003-EΔ866 {co-financed by E.U.-European Social Fund (80%) and the Greek Ministry of Development-GSRT (20%)}.